Did you know that you can navigate the posts by swiping left and right?
What I learnt from snooping on DC++!
04 Dec 2016
. category:
math
.
Comments
#data science
#DC++
#pilani
College Campuses generally have an active intranetwork, where people share and download stuff – DC++ is the lifeline of BITS Pilani, a god-like discovery for first-years and an indispensable tool for the final-years! This unregulated hub of pirated content has come under authorities’ scrutiny in recent times, but has seen widespread support from the student community.
We wonder why!
Last semester, Gyani and I figured out that we could actually track what was being searched on the network, in real-time. Back then, we were building a “Recommender System” based on the users’ shared filelists.
This time around, we ran a script to log all search queries for a whole week – as secretly as we could! As we tried to understand patterns in the data, we decided to build a website with real-time searches being relayed on it. Add User Search Data, and Reverse Search, we have a seemingly viral website – DCWatch(People on campus, head over to 172.17.14.6), logging 500+ Users within 12 hours of launch!
I’ve built a Shiny App, showcasing our analytics on the 7-day data.
So in the seven-day period, from the 14th of November to the 20th of November, we recorded 20,000 searches on Nebula – Our script was not robust enough, and we may have missed a couple thousand because of frequent crashes. I must admit, it was fun watching people search, as me and my wingies laughed all the way!
Firstly, we built a module to classify searches into broad categories – “Explicit”, “English TV”, “Hindi Movies” to name a few. After failing in the implementation of any Machine Learning technique, we resorted to hard-coding lists for each category. Scrape all movies, TV Shows, Pornstars, Games, Softwares, and do a “if x in y” search! The data was too campus-specific for any ML module to work efficiently.
Insights
WordClouds – Everyone’s favorite visualization! A perfect reflection of what Pilani is searching for.
Here is the Wordcloud for the “Explicit” category
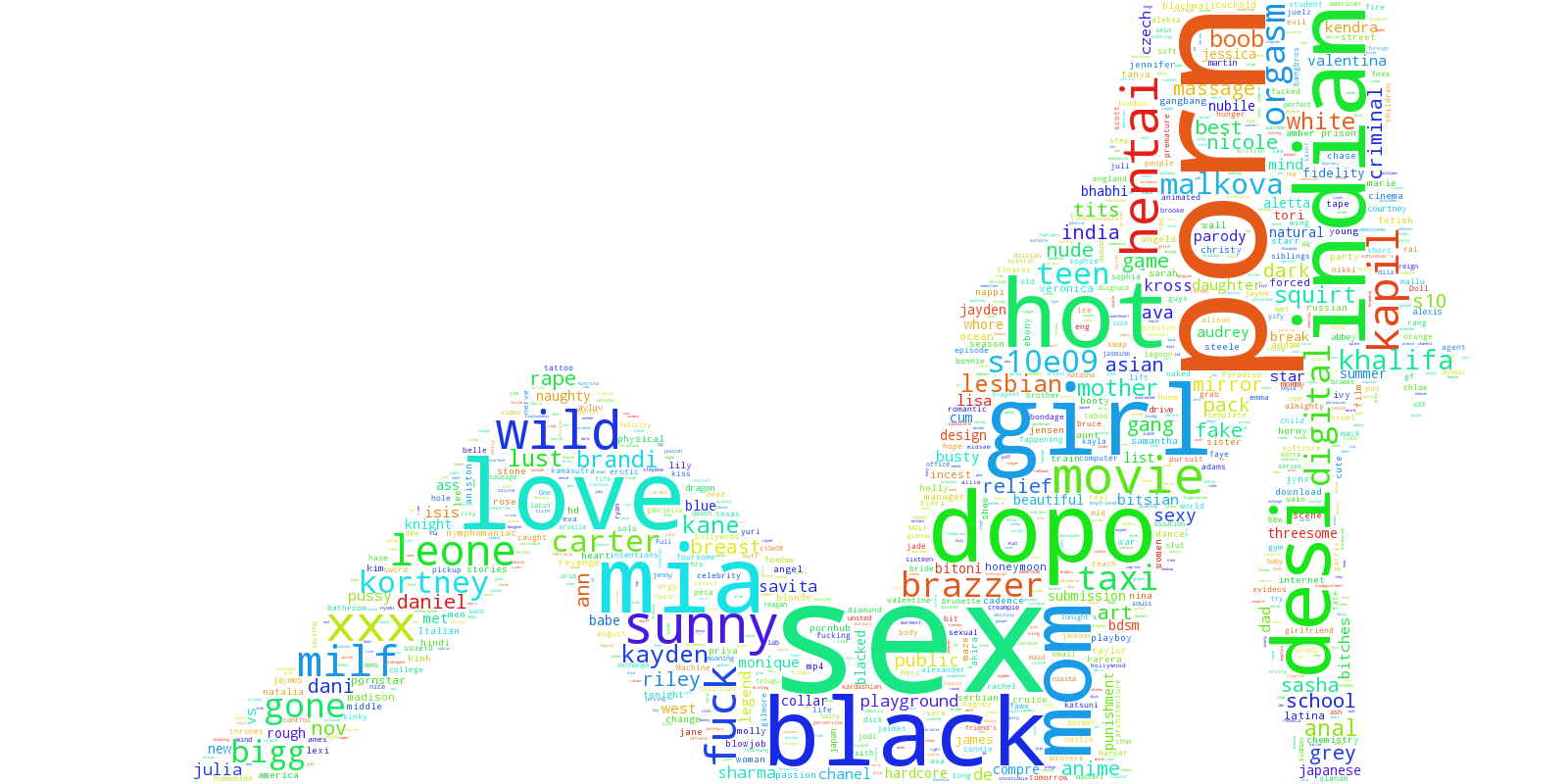
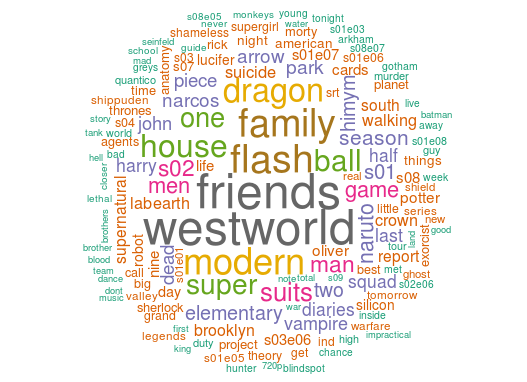
Another one for “English TV Shows”
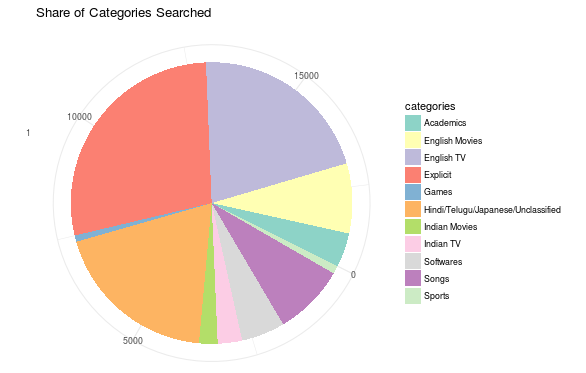
Here, have a look at the dreaded misrepresentative pie-chart!
Another interesting insight we came across was what was being searched at what time! Interestingly, “Sports” peaked at 10A.M, while “Explicit” and “English TV” peaked at 8-10 P.M.
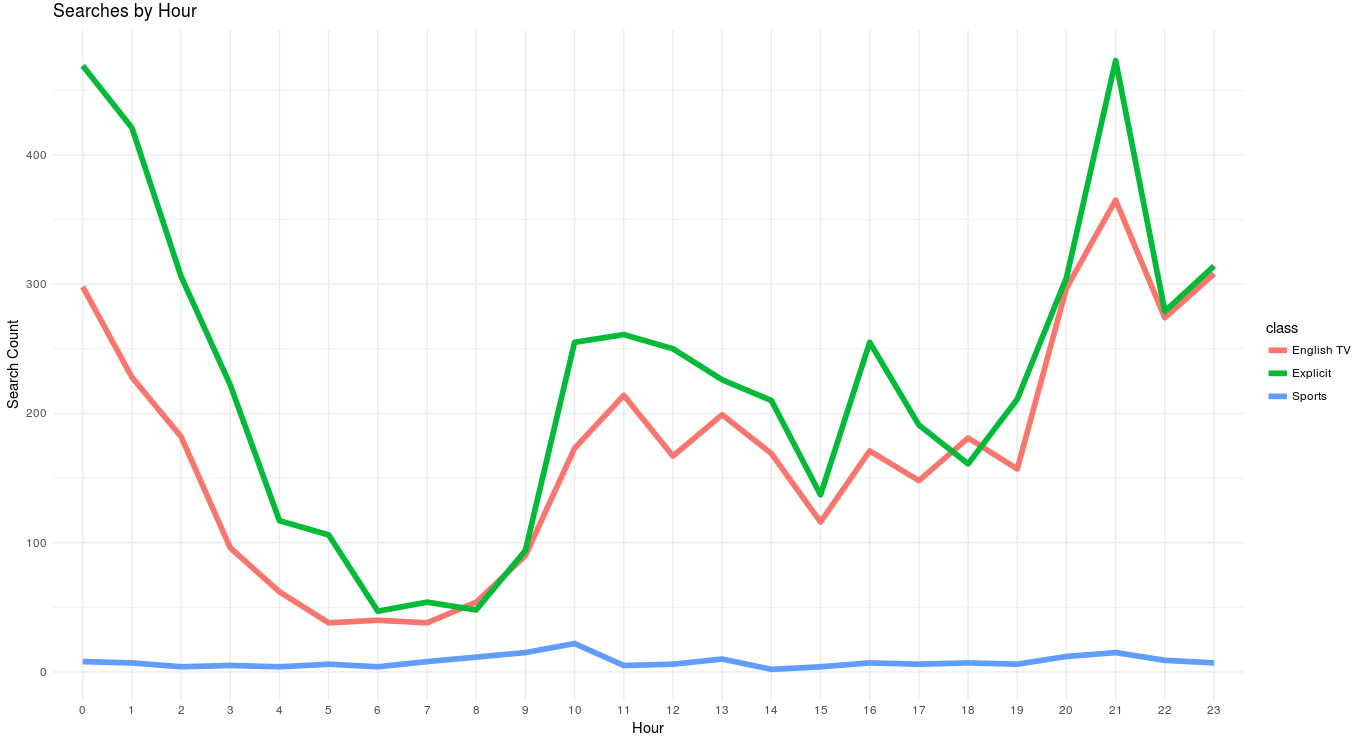
Possible Bias
A high percentage of searches are direct clicks to TTS(via +uploads), which we didn’t account for. Probably, this is why categories like “Sports” and “English TV” are heavily underrepresented! A surprising statistic is the amount of Non-English(Hindi/Telugu/Japanese) search queries, which we couldn’t classify!
Classic cases of sampling error.
What Next?
We have a lot of ideas, like developing a hostel-wise search map – You never know how Ashok Bhawan might behave in comparison to SR. Meera is a different story altogether!
We could clearly see certain search queries trending and then dying within days, “Kapil Sharma”, “Westworld” to name a few. The trend behavior might speak a lot about its growth and popularity on campus!
We’d also like to analyze how and if, the search trends change because of the public launch of DCWatch! Modules for real-time analytics are being developed, hold tight!
If you found this interesting and have an idea to pitch in, do contribute!
Disclaimer
Our sole intention is to analyze the search queries, hopefully you ain’t ashamed of yours :p

Shubhankar is an awesome person. He's Co-Founder at Houseware, building the next generation of Analytics. In his spare time, he likes to go out on runs!